AImoclips: A Benchmark for Evaluating Emotion Conveyance in Text-to-Music Generation
Gyehun Go, Satbyul Han, Ahyeon Choi, Eunjin Choi, Juhan Nam and Jeong Mi Park
Abstract
Recent advances in text-to-music (TTM) generation have enabled controllable and expressive music creation using natural language prompts. However, the emotional fidelity of TTM systems remains largely underexplored compared to human preference or text alignment. In this study, we introduce AImoclips, a benchmark for evaluating how well TTM systems convey intended emotions to human listeners, covering both open-source and commercial models. We selected 12 emotion intents spanning four quadrants of the valence-arousal space, and used six state-of-the-art TTM systems to generate over 1,000 music clips. A total of 111 participants rated the perceived valence and arousal of each clip on a 9-point Likert scale. Our results show that commercial systems tend to produce music perceived as more pleasant than intended, while open-source systems tend to perform the opposite. Emotions are more accurately conveyed under high-arousal conditions across all models. Additionally, all systems exhibit a bias toward emotional neutrality, highlighting a key limitation in affective controllability. This benchmark offers valuable insights into model-specific emotion rendering characteristics and supports future development of emotionally aligned TTM systems.
Method
The method involved a multi-step process to create and evaluate the AImoclips benchmark. First, 12 emotion intents were selected from the valence-arousal space, excluding intermediate values to ensure clear emotional separation. Six state-of-the-art text-to-music (TTM) systems, including both open-source and commercial models, were used to generate 991 ten-second music clips based on these emotion intents. Finally, an online survey was conducted with 111 participants to collect valence and arousal ratings for each clip on a 9-point Likert scale, ensuring a robust human evaluation of the emotional conveyance of the generated music. The images below are displayed along questions to help participants understand the concepts of valence and arousal.


Results
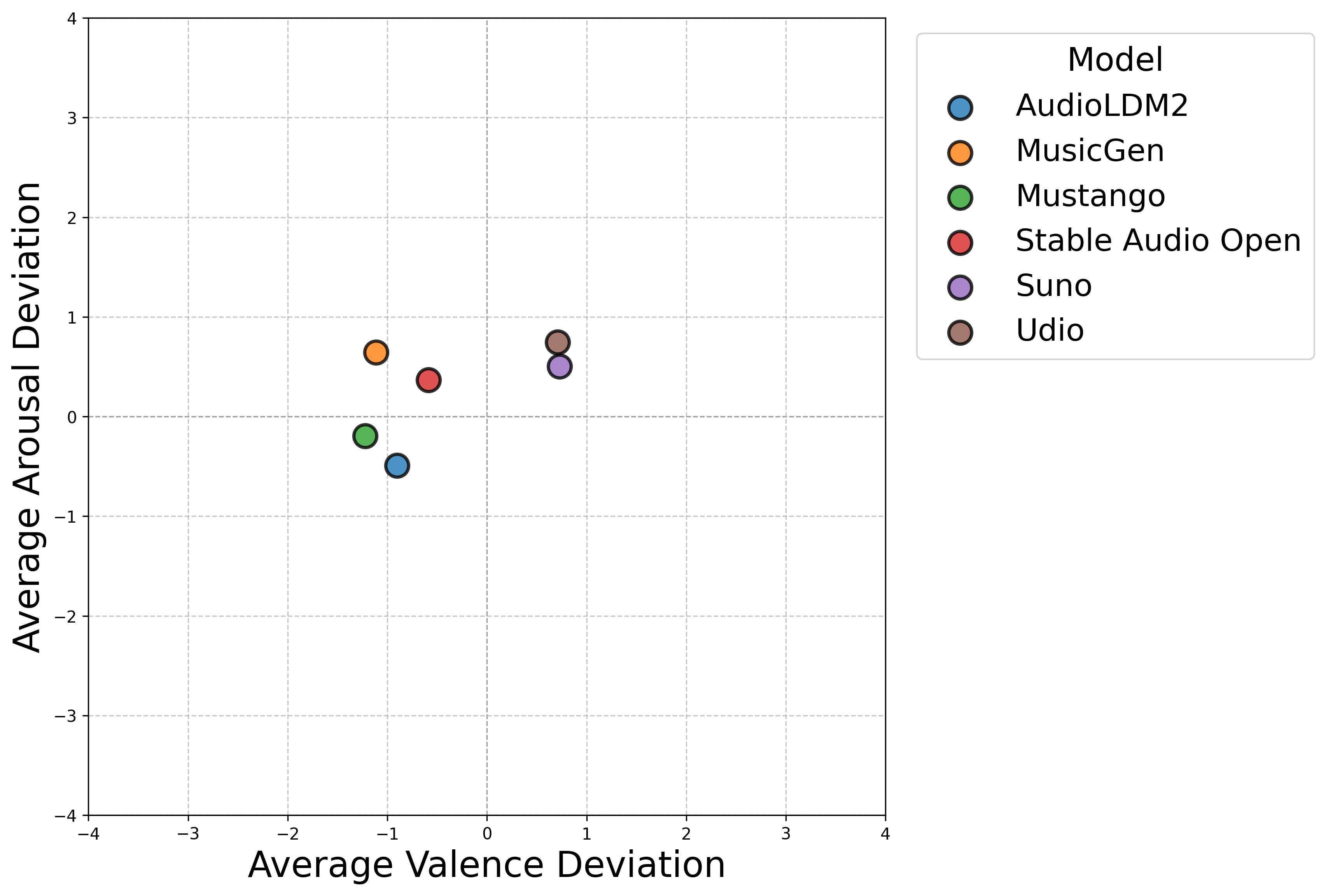
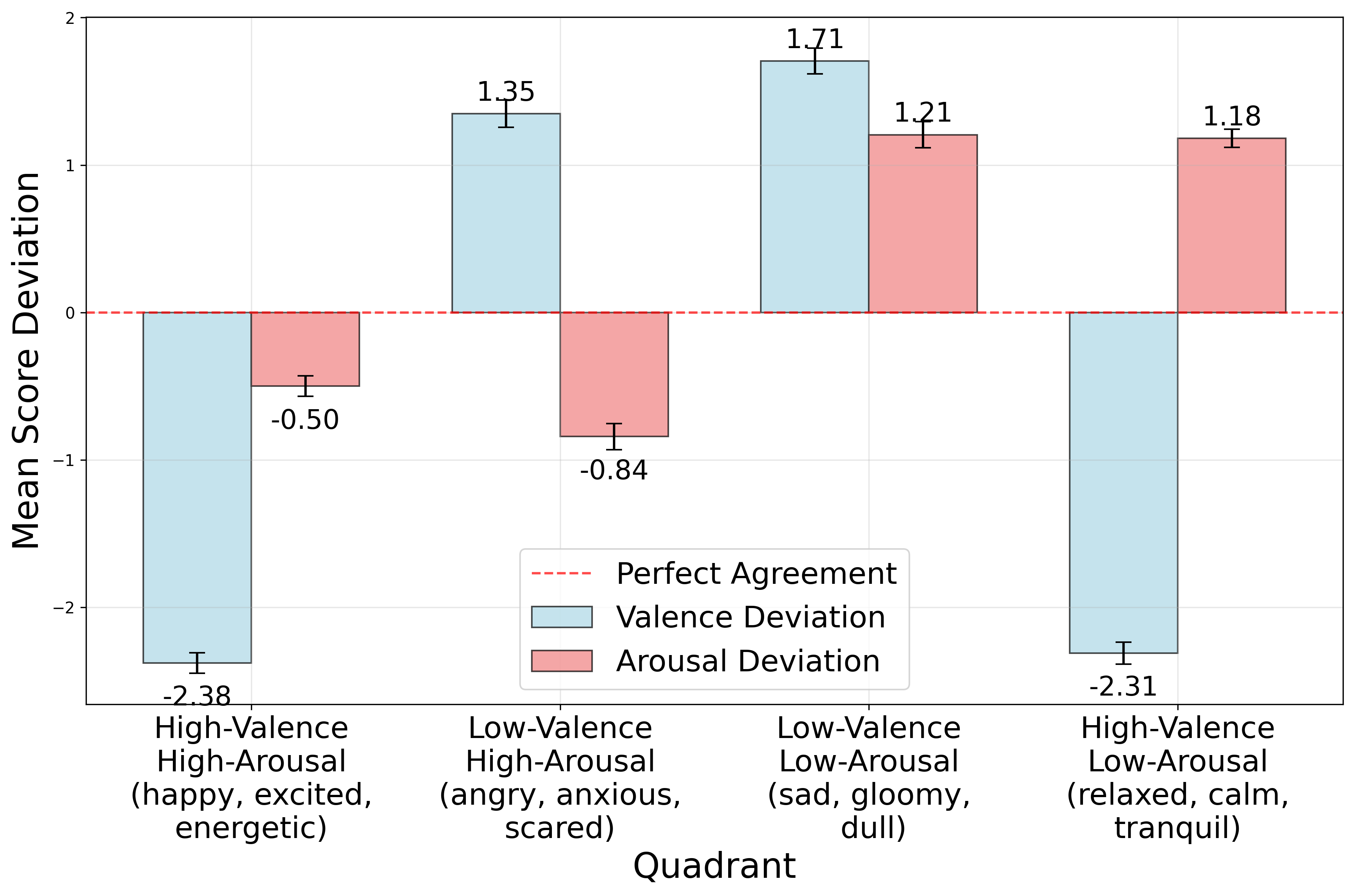
Our analysis reveals significant differences in emotional conveyance across various text-to-music models. Commercial models generally skewed towards higher valence, producing music that was perceived as more positive than intended, whereas open-source models tended to do the opposite. We observed that high-arousal emotions were more accurately conveyed across all systems. A consistent finding was a systemic bias towards emotional neutrality, indicating that current TTM models have difficulty rendering strong, unambiguous emotions. These results underscore the need for improved affective control in future text-to-music generation systems.
Examples
| Music Source | TTM System | Emotion Intent | Valence (Ground Truth vs Rated) | Arousal (Ground Truth vs Rated) |
|---|---|---|---|---|
| AudioLDM 2 | angry | |||
| AudioLDM 2 | gloomy | |||
| AudioLDM 2 | happy | |||
| AudioLDM 2 | relaxed | |||
| MusicGen | angry | |||
| MusicGen | gloomy | |||
| MusicGen | happy | |||
| MusicGen | tranquil | |||
| Mustango | anxious | |||
| Mustango | calm | |||
| Mustango | energetic | |||
| Mustango | sad | |||
| Stable Audio Open | dull | |||
| Stable Audio Open | excited | |||
| Stable Audio Open | relaxed | |||
| Stable Audio Open | scared | |||
| Suno | calm | |||
| Suno | dull | |||
| Suno | energetic | |||
| Suno | scared | |||
| Udio | anxious | |||
| Udio | excited | |||
| Udio | sad | |||
| Udio | tranquil |